Database setup
There are two types of BIGSdb database:
sequence definition databases, containing
allele sequences and their identifiers
scheme data, e.g. MLST profile definitions
isolate databases, containing
isolate provenance metadata
genome sequences
allele designations for loci defined in sequence definition databases.
These two databases are independent but linked. A single isolate database can communicate with multiple sequence definition databases and vice versa. Different access restrictions can be placed on different databases.
Databases are described in XML files telling BIGSdb everything it needs to know about them. Isolate databases can have any fields defined for the isolate table,allowing customisation of metadata - these fields are described in the XML file (config.xml) and must match the fields defined in the database itself.
Creating databases
There are templates available for the sequence definition and isolate databases. These are SQL scripts found in the sql directory.
To create a database, you will need to log in as the postgres user and use these templates. For example to create a new sequence definition database called bigsdb_test_seqdef, navigate to the sql directory and log in as the postgres user, e.g.
sudo su postgres
then
createdb bigsdb_test_seqdef
psql -f seqdef.sql bigsdb_test_seqdef
Create an isolate database the same way:
createdb bigsdb_test_isolates
psql -f isolatedb.sql bigsdb_test_isolates
The standard fields in the isolate table are limited to essential fields required by the system as well as country and year. To add new fields, you need to log in to the database and alter this table. For example, to add fields for age and sex, first log in to the newly created isolate database as the postgres user:
psql bigsdb_test_isolates
and alter the isolate table:
ALTER TABLE isolates ADD age int;
ALTER TABLE isolates ADD sex text;
If you want to use the geography_point field type, used for storing and mapping GPS coordinates, then you will need to install the PostGIS module for PostgreSQL and enable this within the database as follows:
CREATE EXTENSION postgis;
To create a geography_point field for location alter the isolate table as below:
ALTER TABLE isolates ADD location geography(POINT,4326);
[SRID 4326 represents spatial data using longitude and latitude coordinates on the Earth’s surface.]
Fields can also be linked to a GPS lookup table and can then be mapped. If this is enabled then you need to ensure that PostGIS is installed and create the lookup table by running the isolatedb_geocoding.sql script against the isolate database with the following:
psql -f isolatedb_geocoding.sql bigsdb_test_isolates
Remember that any fields added to the table need to be described in the config.xml file for this database.
The xml directory of the software archive contains example XML files for sequence definition and isolate databases (rename these to config.xml). The isolates_config.xml file contains the minimum required isolate table fields and matches the isolate table that will be generated using the isolatedb.sql SQL script.
Database-specific configuration
Each BIGSdb database on a system has its own configuration directory, by default in /etc/bigsdb/dbases. The database has a short configuration name used to specify it in a web query and this matches the name of the configuration sub-directory, e.g. http://pubmlst.org/cgi-bin/bigsdb/bigsdb.pl?db=pubmlst_neisseria_isolates is the URL of the front page of the PubMLST Neisseria isolate database whose configuration settings are stored in /etc/bigsdb/dbases/pubmlst_neisseria_isolates. This database sub-directory contains a number of optional files:
config.xml- the database configuration file. Fields defined here correspond to fields in the isolate table of the database.banner.html - optional file containing text that will appear as a banner within the database index pages. HTML markup can be used within this text.
header.html - HTML markup that is inserted at the top of all pages. This can be used to set up site-specific menubars and logos.
footer.html - HTML markup that is inserted at the bottom of all pages.
curate_header.html - HTML markup that is inserted at the top of all curator’s interface pages.
curate_footer.html - HTML markup that is inserted at the bottom of all curator’s interface pages.
profile_submit.html - HTML markup for text that is inserted in to the submission interface prior to profile submission finalization. This can be used to add specific instructions such as the requirement to make an isolate submission.
allele_submit.html - HTML markup for text that is inserted in to the submission interface prior to allele submission finalization. This can be used to add specific instructions such as the requirement to attach Sanger trace files.
isolate_submit.html - HTML markup for text that is inserted in to the submission interface prior to isolate submission finalization. This can be used to add specific instructions such as the request to also make a new profile submission if the isolate has a new profile.
profile_curate.html - HTML markup for text that is inserted on submission curation page if profile submissions are pending. This can be used to add specific information to curators.
allele_curate.html - HTML markup for text that is inserted on submission curation page if allele submissions are pending. This can be used to add specific information to curators.
isolate_curate.html - HTML markup for text that is inserted on submission curation page if isolate submissions are pending. This can be used to add specific information to curators.
registration_success.txt - Text file containing message content to be used in an automated E-mail when granting access to a user who has requested access to the database using the site-wide account system (where auto-registration is not enabled).
registration.html - HTML markup for text that will appear on the login page for the current database. This appears right before the “Log in” button.
The header and footer files can alternatively be placed in the root directory of the web site, or in /etc/bigsdb, for site-wide use. If files exist in multiple locations, they are used in the following order of preference: database config directory > web root directory > /etc/bigsdb.
There are four additional files, site_header.html, site_footer.html, curate_site_header.html and curate_site_footer.html which are used when either bigsdb.pl or bigscurate.pl are called without a database configuration. These should be placed in the root directory of the web site or in /etc/bigsdb.
You can also add HTML meta attributes (such as a favicon) by including a file called meta.html in the database configuration directory. For example to set a favicon this file can contain something like the following:
<link rel="shortcut icon" href="/favicon.ico" type="image/ico" />
These attributes will appear in the <head> section of the HTML page.
XML configuration attributes used in config.xml
The following lists describes the attributes used in the config.xml file that is used to describe databases.
Isolate database XML attributes
Please note that database structure described by the field elements must match the physical structure of the database isolate table. Required attributes are in bold:
<db>
Top level element. Contains child elements: system and field.:
<system>
Any value set here can be overridden in a system.overrides file.
authentication
Method of authentication: either ‘builtin’ or ‘apache’. See user authentication.
db
Name of database on system.
dbtype
Type of database: either ‘isolates’ or ‘sequences’.
description
Description of database used throughout interface (see also ‘formatted_description’).
align_limit
Overrides the sequence export record alignment limit in the Sequence Export plugin. Default: ‘200’.
all_plugins
Enable all appropriate plugins for database: either ‘yes’ or ‘no’, default ‘no’.
alternative_codon_tables
Enable alternative codon tables: either ‘yes’ or ‘no’. Set to ‘yes’ to allow individual isolates to use a different codon table than the default (defined by the ‘codon_table’ attribute), default is ‘no’.
annotation
Semi-colon separated list of accession numbers with descriptions (separated by a |), eg. ‘AL157959|Z2491;AM421808|FAM18;NC_002946|FA 1090;NC_011035|NCCP11945;NC_014752|020-06’. Currently used only by Genome Comparator plugin.
BLAST
Enable Blast plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the Blast plugin can be disabled by setting this attribute to ‘no’.
BURST
Enable BURST plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the BURST plugin can be disabled by setting this attribute to ‘no’.
cache_schemes
Enable automatic refreshing of scheme field caches when batch adding new isolates: either ‘yes’ or ‘no’, default ‘no’.
See scheme caching.
CodonUsage
Enable Codon Usage plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the Codon Usage plugin can be disabled by setting this attribute to ‘no’.
codon_table
Set the id of the global codon table to use. See https://www.ncbi.nlm.nih.gov/Taxonomy/Utils/wprintgc.cgi for a list with the of ids and their description. This can be overridden on a per-isolate basis if alternative_start_codons is set to ‘yes’. Default value is “11”.
codon_usage_limit
Overrides the record limit for the Codon Usage plugin. Default: ‘500’.
contig_analysis_limit
Overrides the isolate number limit for the Contig Export plugin. Default: ‘1000’.
ContigExport
Enable contig export plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the contig export plugin can be disabled by setting this attribute to ‘no’.
country_field
Sets the field in which country is stored. Default: ‘country’. This is needed for mapping.
curate_config
The database configuration that should be used for curation if different from the current configuration. This is used when the submission system is being used so that curation links in the ‘Manage submissions’ pages for curators load the correct database configuration.
curate_link
URL to curator’s interface, which can be relative or absolute. This will be used to create a link in the public interface dropdown menu.
curate_path_includes
Partial path of the bigscurate.pl script used to curate the database. See user authentication.
curate_script
Relative web path to curation script. Default ‘bigscurate.pl’ (version 1.11+).
This is only needed if automated submissions are enabled. If bigscurate.pl is in a different directory from bigsdb.pl, you need to include the whole web path, e.g. /cgi-bin/private/bigsdb/bigscurate.pl.
curators_only
Set to ‘yes’ to prevent ordinary authenticated users having access to database configuration. This is only effective if read_access is set to ‘authenticated_users’. This may be useful if you have different configurations for curation and querying with some data hidden in the configuration used by standard users. Default ‘no’.
daily_pending_submissions
Overrides the daily limit on pending submissions that a user can submit via the web submission system. Default: ‘15’.
daily_rest_submissions_limit
Overrides the limit on number of submissions that can be made to the database via the RESTful interface. This is useful to prevent flooding of the submission system by aberrant scripts. Default: ‘100’.
default_access
The default access to the database configuration, either ‘allow’ or ‘deny’. If ‘allow’, then specific users can be denied access by creating a file called ‘users.deny’ containing usernames (one per line) in the configuration directory. If ‘deny’ then specific users can be allowed by creating a file called ‘users.allow’ containing usernames (one per line) in the configuration directory. See default access.
default_private_records
The default number of private isolate records that a user can upload. The user account must have a status of either ‘submitter’, ‘curator’, or ‘admin’. This value is used to set the private_quota field when creating a new user record (which can be overridden for individual users). Changing it will not affect the quotas of existing users. Default: ‘0’.
default_seqdef_config
Isolate databases only: Name of the default seqdef database configuration used with this database. Used to automatically fill in details when adding new loci.
default_seqdef_dbase
Isolate databases only: Name of the default seqdef database used with this database. Used to automatically fill in details when adding new loci.
default_seqdef_script
Isolate databases only: URL of BIGSdb script running the seqdef database (default: ‘/cgi-bin/bigsdb/bigsdb.pl’).
delete_retire_only
Set to ‘yes’ to retire the id of any isolate that is deleted. This prevents re-use of ids. This setting will override the global setting in bigsdb.conf.
disable_updates
Set to ‘yes’ to prevent updates. This is useful when moving databases or temporarily running on a backup server.
disable_update_message
Message shown when updates are disabled.
display_assembly_checks
Add a column to the isolate table results to display the results of assembly checks (if set up). This can be overridden by user preferences. Set ‘yes’ or ‘no’, default is ‘no’.
display_contig_count
Add a column to the isolate table results to display the number of contigs in the record’s assembly. This can be overridden by user preferences. Set ‘yes’ or ‘no’, default is ‘no’.
display_seqbin_size
Add a column to the isolate table results to display the total length of a record’s assembly. This can be overridden by user preferences. Set ‘yes’ or ‘no’, default is ‘no’.
eav_fields
Name to call sparsely-populated fields. Default: ‘secondary metadata’.
eav_field_icon
Icon class from FontAwesome to use on isolate info page for sparsely- populated fields. Default ‘fas fa-microscope’.
eav_groups
Comma-separated list of category names that sparsely-populated fields can be grouped in to. If this value is set, a category drop-down list will appear when adding or updating sparsely-populated fields. You can add an icon to appear by following the name with a pipe symbol (|) and an icon class from the FontAwesome library, e.g. ‘Vaccine reactivity|fas fa-syringe,Risk factors|fas fa-smoking’.
export_limit
Overrides the default allowed number of data points (isolates x columns) to export. Default: ‘25000000’.
fast_scan
Sets whether fast mode scanning is enabled via the web interface. This will scan all loci together, using exemplar sequences. In cases where multiple loci are being scanned this should be significantly faster than the standard locus-by-locus scan, but it will take longer for the first results to appear. Allele exemplars should be defined if you enable this option. Set to ‘yes’ to enable. Default: ‘no’.
field_groups
Comma-separated list of category names that standard isolate fields can be grouped in to in the isolate information page. You can add an icon to appear by following the name with a pipe symbol (|) and an icon class from the FontAwesome library, e.g. ‘Antimicrobial resistance|fas fa-capsules’.
fieldgroup1 - fieldgroup10
Allows multiple fields to be queried as a group. Value should be the name of the group followed by a colon (:) followed by a comma-separated list of fields to group, e.g. identifiers:id,strain,other_name.
formatted_description
Markdown formatted description of database. If set, this will be used throughout the HTML interface wherever formatting can be applied (main body of text) and overrides the value set in ‘db_description’. Currently only supports *italics* and **bold**.
genepresence_record_limit
Overrides the record number limit (isolates x loci) for the Gene Presence plugin. Default: 500000 (this can also be set globally in bigsdb.conf).
genepresence_taxa_limit
Overrides the isolate limit for the Gene Presence plugin. Default: 10000 (this can also be set globally in bigsdb.conf).
GenomeComparator
Enable Genome Comparator plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the Genome Comparator plugin can be disabled by setting this attribute to ‘no’.
genome_comparator_limit
Overrides the isolate number limit for the Genome Comparator plugin. Default: 1000 (this can also be set globally in bigsdb.conf).
genome_comparator_max_ref_loci
Overrides the limit on number of loci allowed in a reference genome. Default: 10000.
genome_comparator_threads
The number of threads to use for data gathering (BLAST, database queries) to populate data structure for Genome Comparator analysis. You should not set this to less than 2 as this will prevent job cancelling due to the way isolates are queued. Default: ‘2’.
genome_submissions
Enable genome submissions (automated submission system): either ‘yes’ or ‘no’, default ‘yes’.
To enable, you will also need to set submissions=”yes”. By default, genome submissions are enabled.
hide_unused_schemes
Sets whether a scheme is shown in a main results table if none of the isolates on that page have any data for the specific scheme: either ‘yes’ or ‘no’, default ‘no’.
host
Host name/IP address of machine hosting isolate database, default ‘localhost’.
itol_record_limit
Overrides the maximum number of records that can be included in an ITOL job. Default: 2000 (this can also be set globally in bigsdb.conf).
itol_seq_limit
Overrides the maximum number of sequeneces (records x loci) that can be included in an ITOL job. Default: 100,000 (this can also be set globally in bigsdb.conf).
job_priority
Integer with default job priority for offline jobs (default:5).
job_quota
Integer with number of offline jobs that can be queued or currently running for this database.
labelfield
Field that is used to describe record in isolate info page, default ‘isolate’.
locus_aliases
Display locus aliases and use them in dropdown lists by default: must be either ‘yes’ or ‘no’, default ‘no’. This option can be overridden by a user preference.
locus_superscript_prefix
Superscript the first letter of a locus name if it is immediately following by an underscore, e.g. f_abcZ would be displayed as fabcZ within the interface: must be either ‘yes’ or ‘no’, default ‘no’. This can be used to designate gene fragments (or any other meaning you like).
maindisplay_aliases
Default setting for whether isolates aliases are displayed in main results tables: either ‘yes’ or ‘no’, default ‘no’. This setting can be overridden by individual user preferences.
max_contigs
Number of contigs above which genome submissions will be rejected. Default: 1000
max_total_length
Total length (bp) above which genome submissions will be rejected. Default: 15000000
Microreact
Enable Microreact plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the Microreact plugin can be disabled by setting this attribute to ‘no’. Note that for the plugin to be active, a country field containing a defined list of allowed values and an integer year field must be defined in the isolates table. The plugin also requires microreact_token to be provided in bigsdb.conf.
microreact_country_field
Overrides the field in which country is stored. Default: ‘country’
microreact_record_limit
Overrides the maximum number of records that can be included in a Microreact job. Default: 2000 (this can also be set globally in bigsdb.conf).
microreact_seq_limit
Overrides the maximum number of sequences (records x loci) that can be included in an Microreact job. Default: 100,000 (this can also be set globally in bigsdb.conf).
microreact_year_field
Overrides the field in which year is stored. Default: ‘year’
min_n50
Minimum N50 for genome submissions below which the submission will be rejected. Default: 10000
min_total_length
Minimum total length (bp) for genome submissions below which the submission will be rejected. Default: 1000000.
min_genome_size
Size in bp that is the minimum size of the sequence bin considered to represent a whole genome. This is used in the REST interface to differentiate records with genomes. You can also pass a ‘genomes=1’ attribute to the an isolate query form and this will populate the appropriate search to return genome records.
new_version
Set to ‘no’ to prevent copying field value when creating a new version of the isolate record.
noshow
Comma-separated list of fields not to use in breakdown statistic plugins.
no_publication_filter
Isolate databases only: Switches off display of publication filter in isolate query form by default: either ‘yes’ or ‘no’, default ‘no’.
only_sets
Don’t allow option to view the ‘whole database’ - only list sets that have been defined: either ‘yes’ or ‘no’, default ‘no’.
password
Password for access to isolates database, default ‘remote’.
pcr_limit
Overrides the isolate number limit for the in silico PCR plugin. Default: ‘10000’.
PhyloViz
Enable third party PhyloViz plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the PhyloViz plugin can be disabled by setting this attribute to ‘no’.
port
Port number that the isolate host is listening on, default ‘5432’.
privacy
Displays E-mail address for sender in isolate information page if set to ‘no’. Default ‘yes’.
public_login
Optionally allow users to log in to a public database - this is useful as any jobs will be associated with the user and their preferences will also be linked to the account. Set to ‘no’ to disable. Default ‘yes’.
query_script
Relative web path to bigsdb script. Default ‘bigsdb.pl’ (version 1.11+).
This is only needed if automated submissions are enabled. If bigsdb.pl is in a different directory from bigscurate.pl, you need to include the whole web path, e.g. /cgi-bin/bigsdb/bigsdb.pl.
read_access
Describes who can view data: either ‘public’ for everybody or ‘authenticated_users’ for anybody who has been able to log in. Default ‘public’.
related_databases
Semi-colon separated list of links to related BIGSdb databases on the system. This should be in the form of database configuration name followed by a ‘|’ and the description, e.g. ‘pubmlst_neisseria_seqdef|Typing’. This is used to populate the menu items.
remote_contigs
Optionally allow the use of remote contigs. These are stored in a remote BIGSdb database, accessible via the RESTful API. Set to ‘yes’ to enable.
rest_kiosk
If ‘kiosk’ attribute is set, then the REST interface will be disabled for the configuration unless a value is set here. The only supported value currently is ‘sequenceQuery’ which will enable API routes for querying sequences.
rMLSTSpecies
Enable rMLST Species identifier plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the plugin can be disabled by setting this attribute to ‘no’.
script_path_includes
Partial path of the bigsdb.pl script used to access the database. See user authentication.
search_sequence_variation
If loci are defined that have sequence variants (single amino acid or single nucleotide polymorphisms) defined in their respective typing databases, setting this attribute to ‘yes’ will enable the isolate database to be searched by whether alleles found in isolates have these variants or not. This is not enabled by default as there is a small, but unnecessary, performance hit in databases that don’t have any such loci.
separate_dataset
Treat database configuration as though it was a separate database for the purposes of handling submissions and curators: either ‘yes’ or ‘no’, default ‘no’. Submissions will be tagged with the configuration name and will only be visible within that configuration. Curators can be limited to specific configurations by populating the curator_configs table. This also affects whether they are notified of submissions.
SeqbinBreakdown
Enable Sequence bin breakdown plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the plugin can be disabled by setting this attribute to ‘no’. Note that for the plugin to be active, a country field containing a defined list of allowed values and an integer year field must be defined in the isolates table.
seq_export_limit
Overrides the sequence export limit (records x loci) in the Sequence Export plugin. Default: ‘1000000’.
sets
Use sets: either ‘yes’ or ‘no’, default ‘no’.
set_id
Force the use of a specific set when accessing database via this XML configuration: Value is the name of the set.
show_classification_schemes
Show similar isolates determined by classification schemes (if defined) on an isolate record page. Set to either ‘yes’ or ‘no’, default ‘yes’.
show_lincode_matches
Show similar isolates determined by LIN code prefixes (if defined) on an isolate record page. Set to either ‘yes’ or ‘no’, default ‘yes’.
start_codons
Semi-colon separated list of start codons to allow. Note that this list will replace the built-in defaults of ATG, GTG, and TTG, and is used for all functions that require recognising complete coding sequences, such as automated allele definition.
start_id
Defines the minimum record id to be used when uploading new isolate records. This can be useful when it is anticipated that two databases may be merged and it would be easier to do so if the id numbers in the two databases were different. Default: ‘1’.
submissions
Enable automated submission system: either ‘yes’ or ‘no’, default ‘no’ (version 1.11+).
The curate_script and query_script paths should also be set, either in the bigsdb.conf file (for site-wide configuration) or within the system attribute of config.xml.
submissions_deleted_days
Overrides the default number of days before closed submissions are deleted from the system. Default: ‘90’.
TagStatus
Enable Tag status plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the plugin can be disabled by setting this attribute to ‘no’. Note that for the plugin to be active, a country field containing a defined list of allowed values and an integer year field must be defined in the isolates table.
tblastx_tagging
Sets whether tagging can be performed using TBLASTX: either ‘yes’ or ‘no’, default ‘no’.
total_pending_submissions
Overrides the total limit on pending submissions that a user can submit via the web submission system. Default: ‘20’.
user
Username for access to isolates database, default ‘apache’.
user_job_quota
Integer with number of offline jobs that can be queued or currently running for this database by any specific user - this parameter is only effective if users have to log in.
user_projects
Sets whether authenticated users can create their own projects in order to group isolates: either ‘yes’ or ‘no’, default ‘no’.
view
Database view containing isolate data, default ‘isolates’.
views
Comma-separated list of views of the isolate table defined in the database. This is used to set a view for a set, or to restrict loci or schemes to a subset of isolate data.
warn_max_contigs
Set a threshold for the number of contigs in a submitted genome assembly to trigger a warning in the submission interface. This value overrides the value set in bigsdb.conf.
warn_max_total_length
Set an upper threshold for the total size of a submitted genome assembly to trigger a warning in the submission interface.
warn_min_n50
Set a threshold for the minimum N50 value in a submitted genome assembly to trigger a warning in the submission interface. This value overrides the value set in bigsdb.conf.
warn_min_total_length
Set a lower threshold for the total size of a submitted genome assembly to trigger a warning in the submission interface.
webroot
URL of web root, which can be relative or absolute. This is used to provide a hyperlinked item in the dropdown menu. Default ‘/’.
webroot_label
Label text for the breadcrumb link defined by the webroot value. This can be formatted using Markdown. Currently only supports *italics* and **bold**.
<field>
Element content: Field name + optional list <optlist> of allowed values, e.g.:
<field type="text" required="no" length="40" maindisplay="no"
web="http://somewebsite.com/cgi-bin/script.pl?id=[?]" optlist="yes">epidemiology
<optlist>
<option>carrier</option>
<option>healthy contact</option>
<option>sporadic case</option>
<option>endemic</option>
<option>epidemic</option>
<option>pandemic</option>
</optlist>
</field>
type
Data type: int, text, float, bool, date, or geography_point.
allow_submissions
Show in submission template and allow data to be submitted even if field is set as ‘curate_only’. This has no effect on fields that do not have the ‘curate_only’ attribute as these fields are included in submissions by default. This attribute will be overridden if the field has the ‘no_submissions’ attribute set.
annotation_metric
Use field for provenance annotation status metrics. The field should be expected to have a value for records with complete provenance data. Set to ‘yes’ to include.
comments
Comments about the field. These will be displayed in the field description plugin and as tooltips within the curation interface.
curate_only
Set to ‘yes’ to hide field unless logged-in user is a curator or admin. Set the ‘allow_submissions’ attribute to still include the field in the submission template so that it can be included in submissions of new records by standard users.
default
Default value. This will be entered automatically in the web form but can be overridden.
dropdown
Select if you want this field to have its own dropdown filter box on the query page. If the field has an option list it will use the values in it, otherwise all values defined in the database will be included: ‘yes’ or ‘no’, default ‘no’. This setting can be overridden by individual user preferences.
geography_point_lookup
Set to ‘yes’ if this field should be linked to a lookup table of GPS coordinates in order to facilitate mapping within the isolate information page and the Field Breakdown plugin. If any fields have this value set, you need to install the lookup tables by running the isolatedb_geocoding.sql script against the isolate database. This also requires that the PostgreSQL PostGIS module is installed.
group
Fields can be grouped in the isolate information page by specifying the group attribute. The group name must be defined in the field_groups system attribute, otherwise the field will not be shown at all. If undefined, the field will be in the default provenance/primary metadata group.
hide
Completely ignore field. This is useful if you access a database using different configuration files and a field is not relevant to a particular instance. See also Over-riding values.
isolate_display
Set to ‘no’ to not show field on the isolate information page.
length
Length of field, default 12.
log_delete
Sets if the field value will be recorded in the log table if the isolate is deleted. Set to ‘yes’ or ‘no’, default is ‘no’. The id and isolate name are always recorded if deletion is logged.
maindisplay
Sets if field is displayed in the main table after a database search, ‘yes’ or ‘no’, default ‘yes’. This setting can be overridden by individual user preferences.
max
Maximum value for integer and date types. Special values such as CURRENT_YEAR and CURRENT_DATE can be used.
min
Minimum value for integer and date types.
multiple
Sets if field allows multiple values to be set for it, ‘yes’ or ‘no’, default ‘no’. If set to ‘yes’, then the underlying field in the database must be an ARRAY type, e.g. text[].
no_curate
Setting this will hide the field in the curator interface and prevent it from being manually modified. This is useful for fields that are populated by automated scripts or database triggers. Can be ‘yes’ or ‘no’, default ‘no’.
no_submissions
Setting this will hide the field in the submission template. The field is still available if it is added back to the template manually.
optlist
Sets if this field has a list of allowed values, default ‘no’. Surround each option with an <option> tag.
prefixes
Sets the name of a field that this field should be used as a prefix for. That field must be defined. An example of where this would be useful is for defining AMR fields, where one field is a modifier (>,<,=) for a MIC value field. A field with this attribute defined will not be shown as a separate field within the isolate record, but will be displayed as a prefix to the value of the set field. The prefix field will also not be labelled in the curation interface isolate add/update form, but will appear immediately before and inline with the prefixed field.
query
Set to ‘no’ to exclude field from query drop-down lists.
regex
Regular expression used to constrain field values, e.g. regex=”^[A-Z].*$” forces the first letter of the value to be capitalized.
required
Sets if data is required for this field. Allowed values are ‘yes’, ‘no’, ‘expected’, ‘genome_required’ or ‘genome_expected’; default ‘yes’. If set to ‘expected’, the value cannot be left empty when batch adding an isolate record or using the submission system, but a null value can be explicitly set using the value ‘null’. The use of this is to encourage submitters to include a value for this field if it is available, while still allowing empty values if it is not. Setting the value to ‘genome_required’ or ‘genome_expected’ only affect genome submissions.
separator
Optional string to place between field prefix value and field value if the prefixes attribute is defined.
suffix
Optional string that is displayed after value in isolate information page and curation interface. Useful for adding units for numerical values.
userfield
Select if you want this field to have its own dropdown filter box of users (populated from the users table): ‘yes’ or ‘no’, default ‘no’.
web
URL that will be used to hyperlink field values. If [?] is included in the URL, this will be substituted for the actual field value.
Special values
The following special variables can be used in place of an actual value:
CURRENT_DATE: current date in yyyy-mm-dd format
CURRENT_YEAR: the 4 digit value of the current year
Sequence definition database XML attributes
Required attributes are in bold.
<db>
Top level element. Contains child element: system.
<system>
Any value set here can be overridden in a system.overrides file.
authentication
Method of authentication: either ‘builtin’ or ‘apache’. See user authentication.
db
Name of database on system.
dbtype
Type of database: either ‘isolates’ or ‘sequences’.
description
Description of database used throughout interface.
align_limit
Overrides the sequence export record alignment limit in the Sequence Export plugin. Default: ‘200’.
allele_comments
Enable comments on allele sequences: either ‘yes’ or ‘no’, default ‘no’.
This is not enabled by default to discourage the practice of adding isolate information to allele definitions (this sort of information belongs in an isolate database).
allele_flags
Enable flags to be set for alleles: either ‘yes’ or ‘no’, default ‘no’.
alternative_codon_tables
Enable alternative codon tables: either ‘yes’ or ‘no’, default is ‘no’. Set to ‘yes’ to allow different codon tables to be selected when viewing translated sequences or filtering by CDS when uploading new allele definitions.
BURST
Enable BURST plugin: either ‘yes’ or ‘no’. If no value is set then the plugin will not be available unless the all_plugins attribute is set to ‘yes’. If the all_plugins attribute is set to ‘yes’, the BURST plugin can be disabled by setting this attribute to ‘no’.
codon_table
Set the id of the global codon table to use. See https://www.ncbi.nlm.nih.gov/Taxonomy/Utils/wprintgc.cgi for a list with the of ids and their description.
curate_config
The database configuration that should be used for curation if different from the current configuration. This is used when the submission system is being used so that curation links in the ‘Manage submissions’ pages for curators load the correct database configuration.
curate_path_includes
Partial path of the bigscurate.pl script used to curate the database. See user authentication.
curate_script
Relative web path to curation script. Default ‘bigscurate.pl’ (version 1.11+).
This is only needed if automated submissions are enabled. If bigscurate.pl is in a different directory from bigsdb.pl, you need to include the whole web path, e.g. /cgi-bin/private/bigsdb/bigscurate.pl.
curators_only
Set to ‘yes’ to prevent ordinary authenticated users having access to database configuration. This is only effective if read_access is set to ‘authenticated_users’. This may be useful if you have different configurations for curation and querying with some data hidden in the configuration used by standard users. Default ‘no’.
daily_pending_submissions
Overrides the daily limit on pending submissions that a user can submit via the web submission system. Default: ‘15’.
daily_rest_submissions_limit
Overrides the limit on number of submissions that can be made to the database via the RESTful interface. This is useful to prevent flooding of the submission system by aberrant scripts. Default: ‘100’.
delete_retire_only
Set to ‘yes’ to retire the id of any allele or profile that is deleted. This prevents re-use of ids. This setting will override the global setting in bigsdb.conf.
diploid
Allow IUPAC 2-nuclotide ambiguity codes in allele definitions for use with diploid typing schemes: either ‘yes’ or ‘no’, default ‘no’.
disable_seq_downloads
Prevent users or curators from downloading all alleles for a locus (admins always can). ‘yes’ or ‘no’, default ‘no’.
exemplars
Use exemplar sequences in the BLAST caches used for the sequence query pages. This is useful on larger databases as it speeds up the query significantly. Exemplar alleles MUST be defined otherwise sequence queries will fail. ‘yes’ or ‘no’, default ‘no’.
formatted_description
Markdown formatted description of database. If set, this will be used throughout the HTML interface wherever formatting can be applied (main body of text) and overrides the value set in ‘db_description’. Currently only supports *italics* and **bold**.
genome_submissions
Enable link to genome submissions (automated submission system): either ‘yes’ or ‘no’, default ‘yes’.
To enable, you will also need to set isolate_submissions=”yes”.
isolate_database
The config name of the isolate database. This is used to provide a link to isolate submissions. You also need to set isolate_submissions=”yes”.
isolate_submissions
Set to yes to provide a link to isolate submissions. The isolate_database attribute also needs to be set. Default: ‘no’.
job_priority
Integer with default job priority for offline jobs (default:5).
job_quota
Integer with number of offline jobs that can be queued or currently running for this database.
kiosk
Set to a page name to restrict configuration to always start on this page, rather than an index page. This faciliates running in a cut-down kiosk mode that doesn’t allow access to all features. Currently only ‘sequenceQuery’ is supported.
kiosk_allowed_pages
Comma-separated list of pages that the configuration is allowed to show, apart from the page set in the ‘kiosk’ attribute. Example for a sequence query configuration would be ‘sequenceTranslate’ to allow access to the translated sequence page following a query.
kiosk_help
URL to context-sensitive help page.
kiosk_locus
Restrict sequence query to a specific locus or scheme. Use either the locus primary name or ‘SCHEME_X’ where X is the scheme number.
kiosk_no_genbank
Set to “yes” to hide the Genbank accesssion form element in kiosk mode.
kiosk_no_upload
Set to “yes” to hide the sequence file upload in kiosk mode.
kiosk_simple
Remove most explanatory text from kiosk page.
kiosk_text
Alternative text to show on kiosk page.
kiosk_title
Title text to use when running in kiosk mode.
profile_submissions
Enable profile submissions (automated submission system): either ‘yes’ or ‘no’, default ‘no’ (version 1.11+).
To enable, you will also need to set submissions=”yes”. By default, profile submissions are disabled since generally new profiles should be accompanied by representative isolate data, and the profile can be extracted from that.
public_login
Optionally allow users to log in to a public database - this is useful as any jobs will be associated with the user and their preferences will also be linked to the account. Set to ‘no’ to disable. Default ‘yes’.
query_script
Relative web path to bigsdb script. Default ‘bigsdb.pl’ (version 1.11+).
This is only needed if automated submissions are enabled. If bigsdb.pl is in a different directory from bigscurate.pl, you need to include the whole web path, e.g. /cgi-bin/bigsdb/bigsdb.pl.
read_access
Describes who can view data: either ‘public’ for everybody, or ‘authenticated_users’ for anybody who has been able to log in. Default ‘public’.
related_databases
Semi-colon separated list of links to related BIGSdb databases on the system. This should be in the form of database configuration name followed by a ‘|’ and the description, e.g. ‘pubmlst_neisseria_isolates|Isolates’. This is used to populate the menu items.
script_path_includes
Partial path of the bigsdb.pl script used to access the database. See user authentication.
separate_dataset
Treat database configuration as though it was a separate database for the purposes of handling submissions and curators: either ‘yes’ or ‘no’, default ‘no’. Submissions will be tagged with the configuration name and will only be visible within that configuration. Curators can be limited to specific configurations by populating the curator_configs table. This also affects whether they are notified of submissions.
seq_export_limit
Overrides the sequence export limit (records x loci) in the Sequence Export plugin. Default: ‘1000000’.
sets
Use sets: either ‘yes’ or ‘no’, default ‘no’.
set_id
Force the use of a specific set when accessing database via this XML configuration: Value is the name of the set.
start_codons
Semi-colon separated list of start codons to allow. Note that this list will replace the built-in defaults of ATG, GTG, and TTG, and is used for all functions that require recognising complete coding sequences.
submissions
Enable automated submission system: either ‘yes’ or ‘no’, default ‘no’ (version 1.11+).
The curate_script and query_script paths should also be set, either in the bigsdb.conf file (for site-wide configuration) or within the system attribute of config.xml.
submissions_deleted_days
Overrides the default number of days before closed submissions are deleted from the system. Default: ‘90’.
total_pending_submissions
Overrides the total limit on pending submissions that a user can submit via the web submission system. Default: ‘20’.
user_job_quota
Integer with number of offline jobs that can be queued or currently running for this database by any specific user - this parameter is only effective if users have to log in.
webroot
URL of web root, which can be relative or absolute. This is used to provide a hyperlinked item in the dropdown menu. Default ‘/’.
webroot_label
Label text for the breadcrumb link defined by the webroot value. This can be formatted using Markdown. Currently only supports *italics* and **bold**.
Over-riding global defaults set in bigsdb.conf
Certain values set in bigsdb.conf can be over-ridden by corresponding values set in a database-specific config.xml file. These can be set within the system tag like other attributes:
query_script
Relative web path to bigsdb script.
curate_script
Relative web path to curation script.
prefs_db
The name of the preferences database.
auth_db
The name of the authentication database.
tmp_dir
Path to the web-accessible temporary directory.
secure_tmp_dir
Path to the web-inaccessible (secure) temporary directory.
ref_db
The name of the references database.
Over-riding values set in config.xml
Any attribute used in the system tag of the database config.xml file can be over-ridden using a file called system.overrides, placed in the same directory as config.xml. This is very useful as it allows you to set up multiple configs for a database, with the config.xml files symlinked so that any changes to one will be seen in each database configuration. An example of why you may wish to do this would be if you create separate public and private views of the isolate table that filters on some attribute. The system.overrides file uses key value pairs separated by = with the values quoted, e.g.
view="private"
read_access="authenticated_users"
description="Private view of database"
It is also possible to override the allow_submissions, required, maindisplay, default, hide, or curate_only attributes of a particular field using a file called field.overrides. The field.overrides file uses the format ‘field:attribute=”value”’ on each line, e.g.
date_received:required="yes"
Setting field validation rules
Sometimes it may be necessary to restrict the allowed values in one isolate field depending on the values submitted for another field. It is possible to do this using field validation rules. These combine one or more conditions which all have to match for validation to fail and an isolate record upload to be rejected.
An example of this may be if you have an age_year and an age_month field but you only want age_month to be populated if the subject is less than one year old. You can do this as follows.
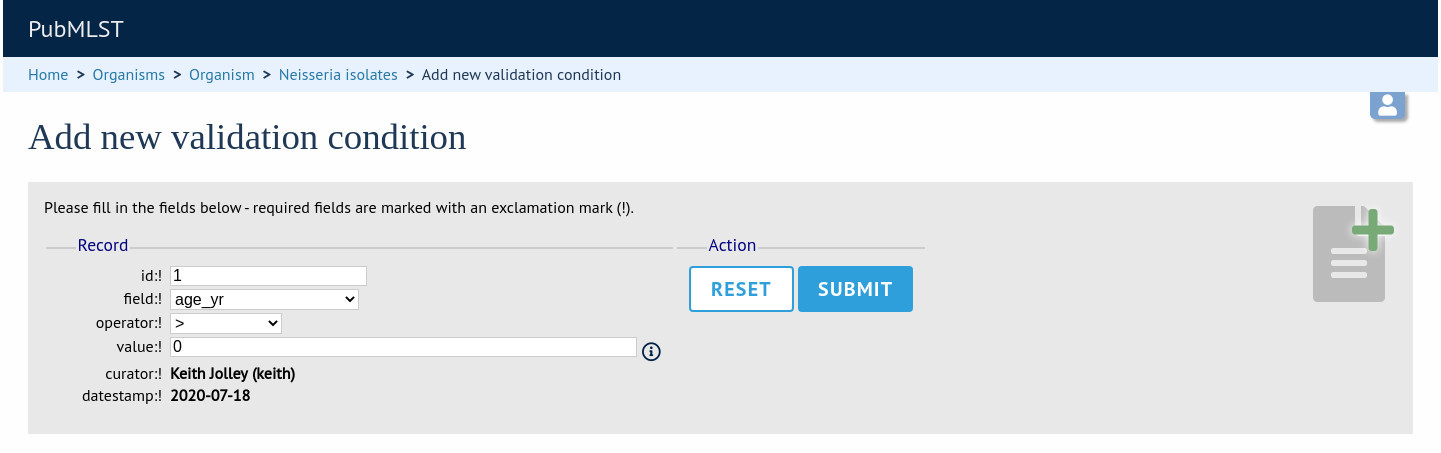
As an admin, on the curator interface, click the ‘Field’ toggle to show the validation table links. Then click ‘Add’ on the ‘Validation conditions’ setting:

Add the following conditions separately:
age_year > 0
age_month NOT null
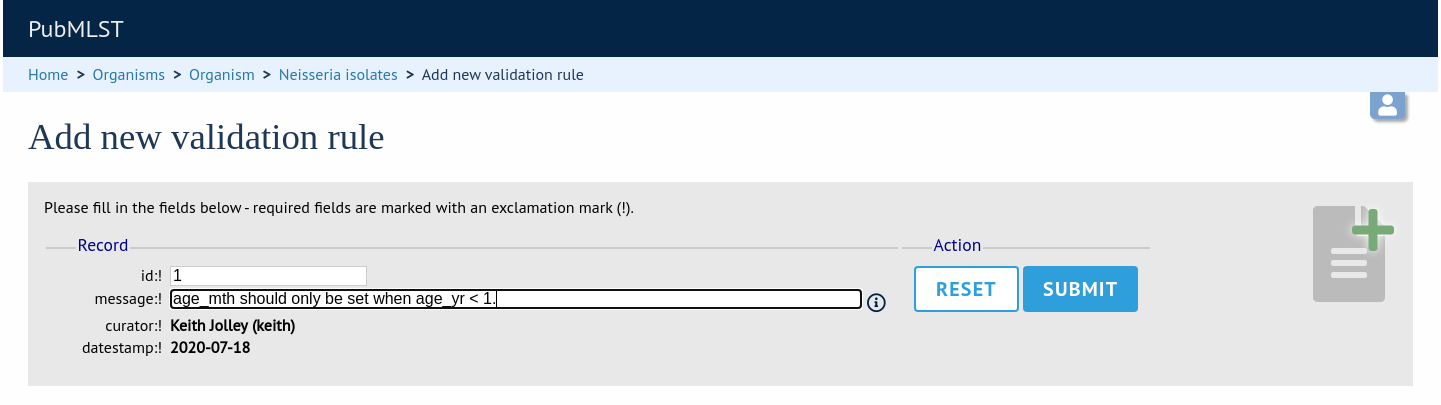
Now add a new ‘Validation rule’, by clicking ‘Add’ on the ‘Validation rules’ setting:

Here you just enter the message that will be returned when the validation fails:
Finally add the conditions to the rule by clicking ‘Add’ on the ‘Rule conditions’ setting:

Select the rule message and the condition from the dropdown boxes:
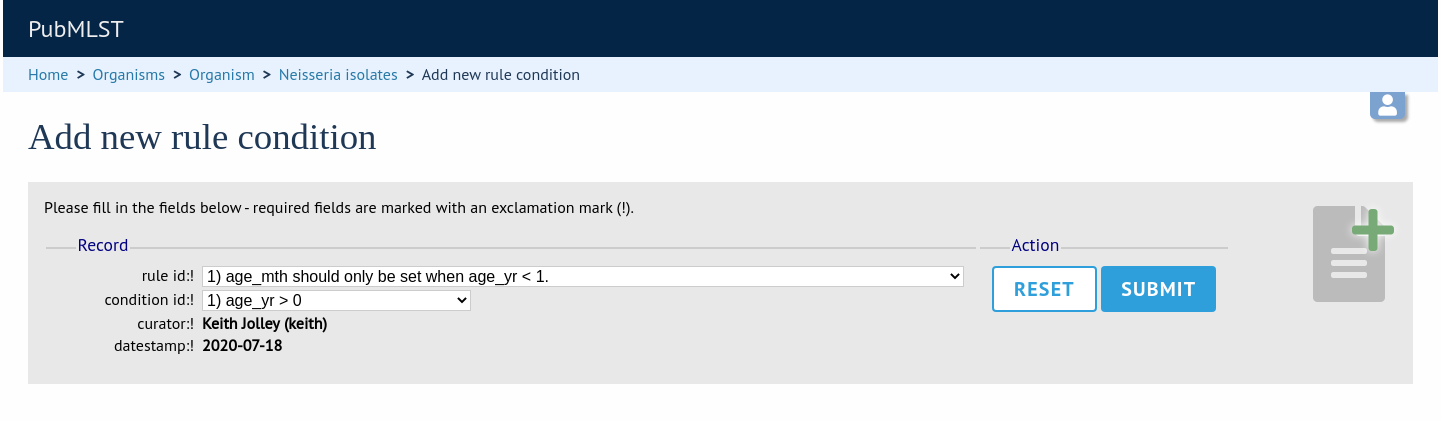
Make sure you do this for each of the conditions that have to match.
Validation checks are performed when adding or updating an isolate record, or when a user submits via the automated submission interface. Currently these checks are not enforced when doing a batch update.
Special condition values
Use the value null to indicate that the field is empty, e.g.
age_month NOT null
Use a field name in square brackets to compare the value in that field, e.g. suppose you have two date fields, ‘date_sampled’ and ‘date_received’, and you want to ensure that ‘date_received’ is not before ‘date_sampled’. You can do this with the following condition:
date_received < [date_sampled]
The two fields have to be of the same data type in order to be compared (you cannot compare a text field to an integer field for example).
Sparsely-populated fields
Commonly used isolate fields should be described in the config.xml file and included as columns within the isolates table. Sometimes, however, you may have a need to record information that is only likely to be found in a minority of records. This can be done more efficiently with the use of sparsely-populated fields. These are stored differently in the database (using an entity-attribute-value [EAV] model) but can still be searched and exported in a similar way to normal fields. There is no limit to the number of such fields that can be defined.
The default name for these fields is ‘secondary metadata’ and this is how they will be grouped in the interface. You can change this by setting the ‘eav_fields’ attribute in the system tag of config.xml. It is also possible to group these fields in to categories - these can be defined with a comma-separated list in the ‘eav_groups’ attribute in the system tag of config.xml.
You will need to be an admin to define sparely-populated fields. Make sure that the ‘Fields’ toggle is selected on the curators’ page. Click the add (+) button on the ‘Sparse fields’ function.

Fill in the form and click ‘Submit’.
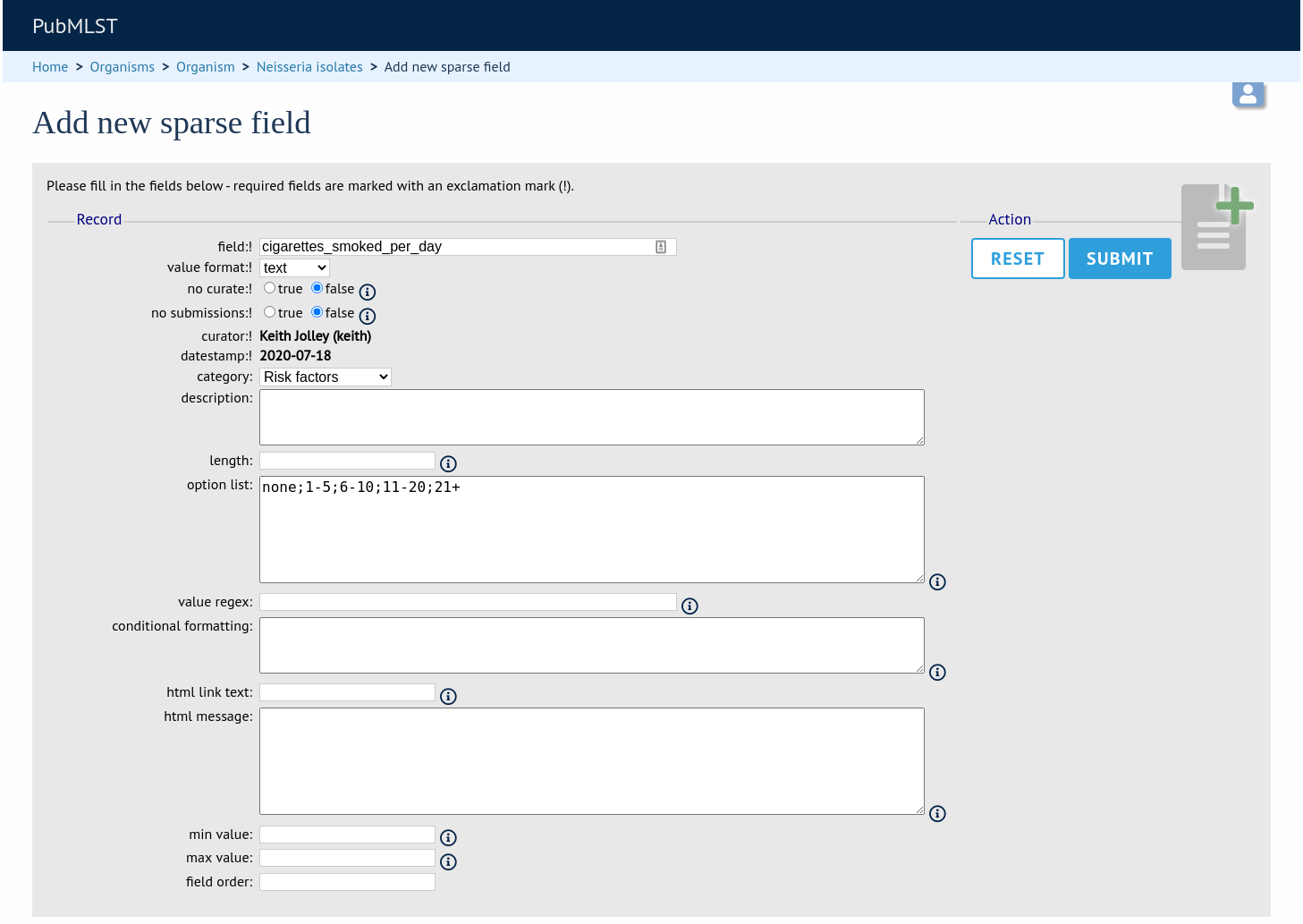
Field options are:
field
name of field
value_format
date type - either integer, float, text, date or boolean.
no_curate
Set to true to prevent user updates of fieldThis setting could be used if the value is calculated by an external script rather than entered by a curator.
no_submissions
Set to true to prevent the field being listed in the submissions template.
description
Tooltip text that will appear on curator forms.
length
Restrict allowed length of value.
option_list
Semi-colon separated list of allowed values.
value_regex
Regular expression that can constrain allowed values.
conditional_formatting
Semi-colon separated list of values - each consisting of the value, followed by a pipe character (|) and HTML to display instead of the value. If you need to include a semi-colon within the HTML, use two semi-colons (;;) otherwise it will be treated as the list separator.’
html_link_text
This defines the text that will appear on an information link that will trigger a slide-in message (if defined int the next field). Default is ‘info’.
html_message
This message will slide-in on the isolate information page when the field value is populated and the information link is clicked. Full HTML formatting is supported.
min_value
Valid for number fields only.
max_value
Valid for number fields only.
field_order
Integer indicating the order that fields should be displayed. If this is not set they will appear alphabetically.
Kiosk mode
Kiosk mode allows you to run a cut-down interface that offers a single main functionality. Currently, only a sequence query page is supported. The interface is locked down so that only specified functionality is supported and data cannot be exported.
See the kiosk_* attributes in config.xml.
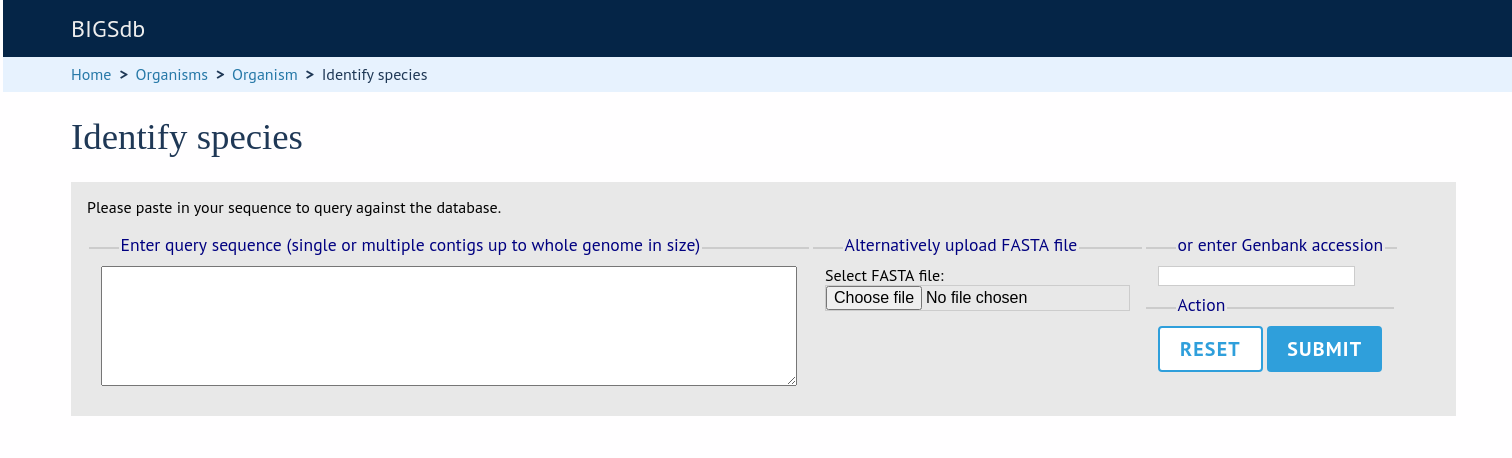
As an example, the following settings are used for the rMLST ‘Identify species’ tool at https://pubmlst.org/rmlst/. The database usually requires a user to log in, but this tool offers a restricted functionality without logging in.
kiosk="sequenceQuery"
kiosk_allowed_pages="sequenceTranslate"
kiosk_title="Identify species"
kiosk_locus="SCHEME_1"
kiosk_simple="yes"
kiosk_no_upload="no"
kiosk_no_genbank="no"
rest_kiosk="sequenceQuery"
When you go to this example kiosk page you see only the sequence query page and trying to access any other functionality is prevented.
The rest_kiosk attribute enables queries to also be performed using the RESTful API which will be similarly locked down.
User authentication
You can choose whether to allow Apache to handle your authentication or use built-in authentication.
Apache authentication
Using apache to provide your authentication allows a flexible range of methods and back-ends (see the Apache authentication HowTo for a start, or any number of tutorials on the web).
At its simplest, use a .htaccess file in the directory containing the bigscurate.pl (and bigsdb.pl for restriction of read-access) script or by equivalent protection of the directory in the main Apache server configuration. It is important to note however that, by default, any BIGSdb database can be accessed by any instance of the BIGSdb script (including one which may not be protected by a .htaccess file, allowing public access). To ensure that only a particular instance (protected by a specific htaccess directive) can access the database, the following attributes can be set in the system tag of the database XML description file:
script_path_includes: the BIGSdb script path must contain the value set.
curate_path_includes: the BIGSdb curation script path must contain the value set.
For public databases, the ‘script_path_includes’ attribute need not be set.
To use apache authentication you need to set the authentication attribute in the system tag of the database XML configuration to ‘apache’.
Built-in authentication
BIGSdb has its own built-in authentication, using a separate database to store password and session hashes. The advantages of using this over many forms of apache authentication are:
Users are able to update their own passwords.
Passwords are not transmitted over the Internet in plain text.
When a user logs in, the server provides a random one-time session variable and the user is prompted to enter their username and password. The password is encrypted within the browser using a Javscript one-way hash algorithm, and this is combined with the session variable and hashed again. This hash is passed to the server. The server compares this hash with its own calculated hash of the stored encrypted password and session variable that it originally sent to the browser. Implementation is based on perl-md5-login. Stored passwords are salted and hashed using bcrypt.
To use built-in authentication you need to set the authentication attribute in the system tag of the database XML configuration to ‘builtin’.
Setting up the admin user
The first admin user needs to be manually added to the users table of the database. Connect to the database using psql and add the following (changing details to suit the user).:
INSERT INTO users (id, user_name, surname, first_name, email, affiliation, status, date_entered,
datestamp, curator) VALUES (1, 'keith', 'Jolley', 'Keith', 'keith.jolley@biology.ox.ac.uk',
'University of Oxford, UK', 'admin', 'now', 'now', 1);
If you are using built-in authentication, set the password for this user using the add_user.pl script. This hashes the password and stores this within the authentication database. Other users can be added by the admin user from the curation interface accessible from http://your_website/cgi-bin/private/bigscurate.pl?db=test_db (or wherever you have located your bigscurate.pl script).
Retrieving PubMed citations from NCBI
Publications listed in PubMed can be associated with individual isolate records, profiles, loci and sequences. Full citations for these are stored within a local reference database, enabling these to be displayed within isolate records and searching by publication and author. This local database is populated by a script that looks in BIGSdb databases for PubMed records not locally stored and then requests the full citation record from the PubMed database.
The script is called retrieve_pubmed_records.pl and can be found in the scripts/maintenance directory.
Simply run the script either as the ‘postgres’ user or an account that is allowed to connect as the postgres user.
This should be run periodically from a CRON job, e.g. every hour.
Configuring access to remote contigs
It is possible for isolate records to have contigs in an external BIGSdb database. These must be accessible via the RESTful API. The advantage of this is that it enables multiple isolate databases to use the same genome assemblies without having to duplicate the storage of those assemblies. If access to the external database requires authenticated access, OAuth settings can be set to enable contig retrieval.
To enable remote contigs, set the remote_contigs attribute in the <system> tag of config.xml, i.e.
remote_contigs = "yes"
Setting up authentication
A client key for the BIGSdb remote contig manager needs to be generated. This can be done using the create_client_credentials.pl script, e.g.
create_client_credentials.pl --a 'BIGSdb remote contig manager' --insert
This will generate a client id (key) and a client secret and add them to the authentication database.
You will then need to obtain an access token and access secret using the client key and secret with the get_oauth_access_token.pl script. You will need to enter the API database URI (e.g. http://rest.pubmlst.org/db/pubmlst_rmlst_isolates) and the web database URL (e.g. https://pubmlst.org/bigsdb?db=pubmlst_rmlst_isolates). You will then be prompted to follow a link and log in to the database with your user credentials. A verification code will be generated. You need to enter this in to the script when prompted. An access token and secret will be returned to you.
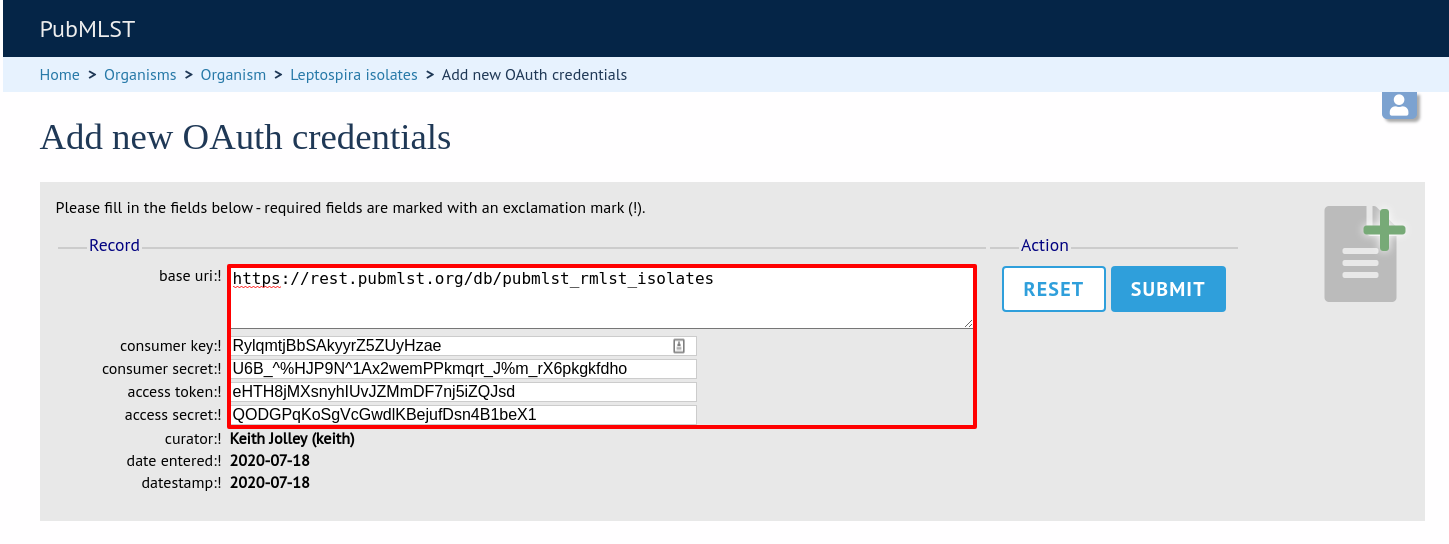
From the curators’ page, click the oauth credentials add link in the administrator settings. This function is normally hidden, so you may need to click the ‘Misc’ toggle to display it.

Populate the OAuth_credentials table with the client key/secret and access token/secret. You should also enter the root REST URI for the database (e.g. http://rest.pubmlst.org/db/pubmlst_rmlst_isolates).
Processing remote contigs
When remote contigs are first linked to a record, the sequences are downloaded in bulk (without their metadata). This allows the sequence lengths to be recorded as this is needed for various queries and outputs. The curator is then given an option to process the contigs, which involves downloading each contig individually to record metadata including the original designation and the sequence platform used. This may take a while so it may be preferable to perform this task offline. This can be done using the process_remote_contigs.pl script found in the scripts/automation directory. Options for using this script are shown below:
remote_contigs.pl --help
NAME
process_remote_contigs.pl
Download, check length and create checksum contigs stored as URIs
SYNOPSIS
process_remote_contigs.pl --database NAME [options]
OPTIONS
--database NAME
Database configuration name.
--exclude_isolates LIST
Comma-separated list of isolate ids to ignore.
--exclude_projects LIST
Comma-separated list of projects whose isolates will be excluded.
--help
This help page.
--isolates LIST
Comma-separated list of isolate ids to scan (ignored if -p used).
--isolate_list_file FILE
File containing list of isolate ids (ignored if -i or -p used).
--min ID
Minimum isolate id.
--max ID
Maximum isolate id.
--projects LIST
Comma-separated list of project isolates to scan.
--quiet
Only display errors.
.. _setup_dashboard:
Setting up front-end and query dashboards
Dashboards can be used as an alternative front-end to isolate databases. They can also be used to summarise the results of a query. In order to enable dashboards for a particular database, they have to be enabled either globally or specifically for the database configuration. If enabled, users will have the option to toggle between the dashboard and the standard index page.
To enable globally and use the front-end dashboard by default, set the following in bigsdb.conf:
enable_dashboard=1
default_dashboard_view=1
Each of these values can be overridden for a particular database by setting the same attribute in the database config.xml file, with either ‘yes’ or ‘no’, i.e. dashboards can be enabled globally but disabled for a particular database configuration, or disabled globally but enabled for a particular database configuration.
To enable query dashboards, set the following in bigsdb.conf:
query_dashboard=1
Again, this value can be overridden for a particular database by setting the attribute in the database config.xml file, as above. Note that ‘enable_dashboard’ also needs to be enabled.
Defining default dashboards
A default global front-end dashboard can be set up by placing a dashboard_primary.toml file in /etc/bigsdb. This can be overridden for individual database configurations by adding a TOML file (dashboard_primary.toml), in the same format, to the database configuration directory. Any field defined in the TOML file that does not appear within a particular database is ignored.
A default global query dashboard can be similarly set up with a file called dashboard_query.toml. As this dashboard appears above isolate results tables it is preferred that smaller elements are defined, usually with a height of 1.
An example of the format can be seen below.
#Configuration for default front-end dashboard for isolate databases. This
#defines the visual elements that will be included. If field-specific elements
#are defined and that field does not exist in a particular database then it
#will be ignored.
#The default configuration can be overridden for a particular database by
#including a dashboard.toml file, using the same format, in the database
#configuration directory.
#Width can be 1, 2, 3, or 4.
#Height can be 1, 2, or 3.
#Field names have prefixes indicating the field type:
#f_ are standard provenance/primary fields
#e_ are extended attributes with the main field and the attribute separated
# by ||, e.g. e_country||continent.
#eav_ are sparse fields
elements = [
{ #Isolate count.
display = 'record_count',
name = 'Isolate count',
width = 2,
background_colour = '#79cafb',
main_text_colour = '#404040',
watermark = 'fas fa-bacteria',
change_duration = 'month',
url_text = 'Browse isolates',
hide_mobile = 0
},
{ #Genome count (will only display if there are genomes in the database).
display = 'record_count',
name = 'Genome count',
genomes = 1,
width = 2,
background_colour = '#7ecc66',
main_text_colour = '#404040',
watermark = 'fas fa-dna',
change_duration = 'month',
url_text = 'Browse genomes',
post_data = { genomes = 1 },
hide_mobile = 0
},
{
display = 'field',
name = 'Country',
field = 'f_country',
breakdown_display = 'map',
width = 3,
height = 2,
hide_mobile = 1
},
{
#Top 5 list of continents (Geocoding should be set up with default country
#list linked to continent - see 'Geocoding setup' on admin curator page.
display = 'field',
name = 'Continent',
field = 'e_country||continent',
breakdown_display = 'top',
top_values = 5,
width = 2,
hide_mobile = 1
},
{
name = 'Sequence size',
display = 'seqbin_size',
genomes = 1,
hide_mobile = 1,
width = 2,
height = 1
},
{ #Doughnut chart of species.
display = 'field',
name = 'Species',
field = 'f_species',
breakdown_display = 'doughnut',
height = 2,
width = 2,
hide_mobile = 1
},
{ #Treemap of disease.
display = 'field',
name = 'Disease',
field = 'f_disease',
breakdown_display = 'treemap',
height = 2,
width = 2,
hide_mobile = 1
},
{
#Bar chart of submission years.
display = 'field',
name = 'Year',
field = 'f_year',
breakdown_display = 'bar',
width = 3,
bar_colour_type = 'continuous',
chart_colour = '#126716',
hide_mobile = 1
},
{
#Cumulative chart of submissions by date.
display = 'field',
name = 'Date entered',
field = 'f_date_entered',
width = 2,
breakdown_display = 'cumulative',
hide_mobile = 1
}
]
Attributes
The allowed attributes are listed below.
background_colour
RGB hex code for the background colour, e.g. ‘#79cafb’. This is used only for ‘big number’ fields, e.g. isolate count.
bar_colour_type
categorical - use contrasting colours for bars.
continuous - use the same colour for all bars (set colour use ‘chart_colour’ attibute).
breakdown_display - type of visualisation. Allowed values are:
bar
bar chart - particularly useful for continuous data such as year.
cumulative
cumulative line chart - used for date_entered or datestamp fields.
doughnut
doughut chart
gps_map
GPS map. This can only be used for geography_point fields or fields that are linked to a lookup table of GPS coordinates.
pie
pie chart
top
top values list. You can choose the number of values to display by also setting the top_values attributes to either 3, 5, or 10.
treemap
treemap chart
word
word cloud. This can only be used for fields that have a defined list of allowed values.
map
global map. This can only be used for ‘country’ fields with a defined list allowed values or ‘continent’ fields which are an extended attribute of country.
change_duration
Show the rate of change, e.g. the number of new records in past month. Used for ‘big number’ fields, e.g. isolate count or specific value count. Allowed values are ‘week’, ‘month’, or ‘year’.
chart_colour
RGB hex code for bar or cumulative line charts, e.g. ‘#126716’.
display
Element type. Allowed values are:
field - This is used for most elements.
record_count - Used for isolate count fields.
seqbin_size - Used to display a histogram of genome sizes.
field
The name of the field to display. Different types of field have different prefixes as follows:
Primary isolate field - prefix with ‘f_’, e.g. ‘f_country’.
Secondary metadata fields - prefix with ‘eav_’.
Extended attributes - prefix with ‘e_’, followed by the primary field name, followed by ‘||’ and then the extended attribute name, e.g. for continent linked to country you would use ‘e_country||continent’.
Scheme fields - e.g. clonal complex - prefix with ‘s_’ followed by the scheme id number, then ‘_’, followed by the scheme field name, e.g. for a field called ‘clonal_complex’ defined for scheme 1, you would use ‘s_1_clonal_complex’.
gauge_background_colour
RGB hex code, e.g. ‘#79cafb, for the background colour on a gauge chart.
gauge_foreground_colour
RGB hex code, e.g. ‘#79cafb, for the foreground colour on a gauge chart.
geography_view
Choice of view for GPS maps, either ‘Aerial’ or ‘Map’. Note that Aerial views can only be used if you have a Bing Maps key set in bigsdb.conf.
header_background_colour
RGB hex code, e.g. ‘#79cafb#, for the header background for a top values list.
header_text_colour
RGB hex code, e.g. ‘#79cafb#, for the header text colour for a top values list.
height
Height of element - either 1, 2, or 3.
hide_mobile
Set to 1 to hide element on small mobile devices (width <= 480 pixels).
main_text_colour
RGB hex code, e.g. ‘#79cafb#, for the colour of the text used in big number elements.
marker_colour
RGB hex code, e.g. ‘#79cafb#, or HTML colour value, for the colour of the markers on GPS maps.
marker_size
Size of marker on GPS maps. Allowed values are 0-9.
max_contigs
Number of contigs above which a genome will be rejected in the submission interface.
min_n50
N50 value below which a genome will be rejected in the submission interface.
min_total_length
Minimum length in base pairs below which a genome will be rejected in the submission interface.
name
The name used for the title of the element.
palette
ColorBrewer palette used for map displays. Allowed values are:
blue
green
purple
orange
red
blue/green
blue/purple
green/blue
orange/red
purple/blue
purple/blue/green
purple/red
red/purple
yellow/green
yellow/green/blue
yellow/orange/brown
yellow/orange/red
post_data
Used to pass data attributes for linked queries. Currently only ‘genomes’ is used to specify that isolates should be filtered to those with genome assemblies, e.g. ‘{genomes = 1}’.
specific_value_display
Type of display to use for specific values. Allowed values are:
gauge - gauge chart
number - big number value
specific_values
list of field values to include in count shown in gauge chart or big number display, e.g. ‘[‘Neisseria meningitidis’]’.
url_text
link text to display when hovering over link leading to data query. Only available for isolate count or specific value charts.
visualisation_type
Either ‘breakdown’ (default) or ‘specific values’. You need to then set the visualisation using either the breakdown_display or specific_value_display attribute.
warn_max_contigs
Number of contigs above which a genome will have a warning message shown in the submission interface.
warn_min_n50
N50 value below which a genome will have a warning message shown in the submission interface.
warn_min_total_length
Minimum length in base pairs below which a genome will have a warning shown in the submission interface.
watermark
FontAwesome icon class used for background watermark on big number charts, e.g. ‘fas fa-bacteria’. See https://fontawesome.com/icons?m=free.
width
Width of element - either 1, 2, 3, or 4.
Defining default colours
Sometimes you may wish to maintain consistent colours for specific field values. You can define colours for values by field using an additional configuration file called dashboard_colours.toml that can be placed either in /etc/bigsdb (for global use) or within a database configuration directory. The format is as follows:
'eav_Bexsero_reactivity' = {
'exact match' = '#2ca02c',
'cross-reactive' = '#ff7f0e',
'none' = '#d62728',
'insufficient data' = '#888888',
'No value' = '#aaaaaa'
}
'eav_Trumenba_reactivity' = {
'exact match' = '#2ca02c',
'cross-reactive' = '#ff7f0e',
'none' = '#d62728',
'insufficient data' = '#888888',
'No value' = '#aaaaaa'
}
's_1_clonal_complex' = {
'ST-11 complex' = 'yellow',
'ST-41/44 complex' = 'green'
}
Field names are prefixed as follows:
f_ Standard provenance fields, e.g. f_country
e_ Extended attribute fields, e.g. e_country||continent (continent attribute linked to country)
eav_ Sparely-populated fields, e.g. eav_Bexsero_reactivity
s_ Scheme fields, e.g. s_1_clonal_complex (clonal complex field in scheme 1)
This works for pie, doughnut, bar, and pie charts. Note that if you define any values for a field then any value not defined will be shown as light grey in the visualisation.